Eliminando la Carga Manual de Datos desde PDFs con IA: Un Pipeline Productivo
Un problema muy común: las organizaciones suelen tener carpetas llenas de CVs en PDF y alguien tiene que extraer manualmente la información a una planilla — lento, propenso a errores e imposible de escalar. Construí un pipeline para eliminar esa tarea por completo.
El Costo Real No Es el Tiempo Por Documento
Cuando alguien me dice "la carga de datos toma 15 minutos por CV", el instinto es calcular el ahorro por hora. Pero ese es el marco equivocado. El costo real es lo que no sucede porque el equipo está atascado haciendo transcripción manual — análisis que no se ejecutan, patrones que no se detectan, decisiones que se demoran.
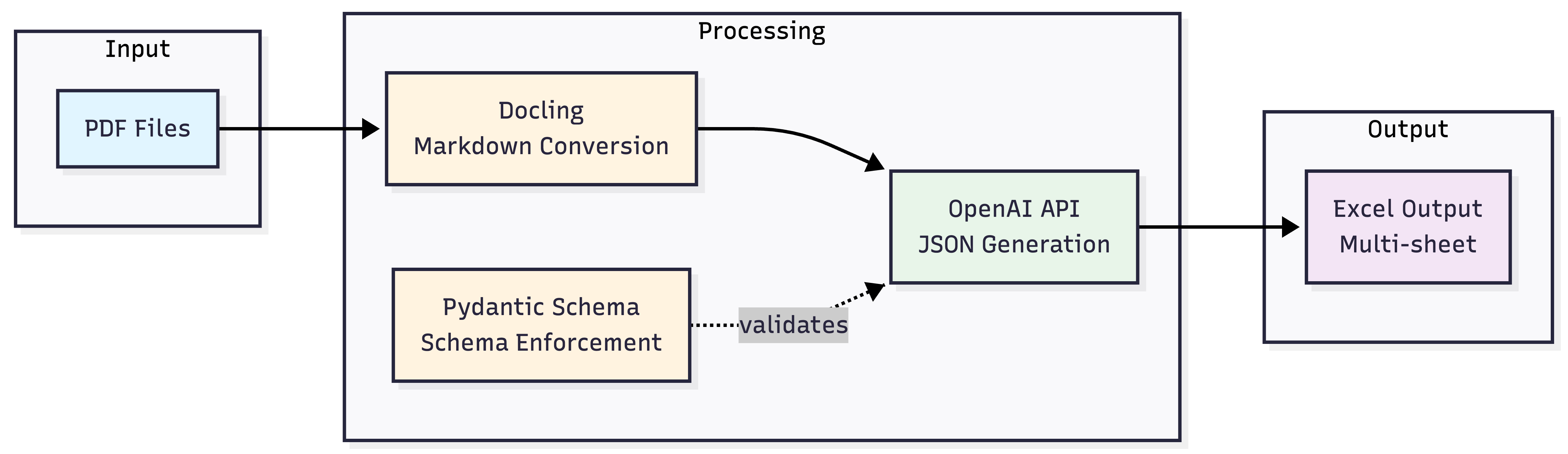
El pipeline que construí procesa un directorio de PDFs, extrae cada campo relevante de cada documento, valida la salida contra un esquema estricto y agrega los resultados a un libro de Excel estructurado. Todo se ejecuta de forma desatendida como un cron job o en un Workflow de Prefect.
De Problema de RRHH a Arquitectura Técnica
El punto de partida fue un pedido real: el equipo de RRHH necesitaba una base de datos de candidatos buscable a partir de una carpeta de CVs. Los documentos no tenían un formato consistente — algunos estaban diseñados con estilos pesados, otros eran exportaciones de texto plano. No había dos CVs iguales.
El pipeline tiene cuatro etapas:
- Descubrimiento de archivos y caché — recorrer el directorio, saltear archivos ya procesados usando hashing SHA-256
- Conversión de PDF a Markdown — parsear cada documento con Docling
- Extracción estructurada — enviar el Markdown a OpenAI con un esquema Pydantic aplicado via Structured Outputs
- Persistencia — agregar los datos extraídos a un libro Excel multi-hoja
Por Qué Markdown Como Formato Intermedio
Enviar bytes crudos de PDF a un LLM no es buena idea en la práctica. Los PDFs son archivos binarios — la extracción de texto depende mucho de cómo se generó el archivo, y la salida suele estar contaminada con artefactos de layout, problemas de codificación de caracteres y orden de lectura desordenado.
Docling convierte PDFs a Markdown limpio, preservando la estructura lógica: encabezados, viñetas, tablas. Esto importa porque el LLM lee el documento más como lo haría un humano, en lugar de intentar parsear un flujo de coordenadas y códigos de glifos. También reduce significativamente el conteo de tokens comparado con enfoques de extracción ingenuos.
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert(file_path)
markdown_text = result.document.export_to_markdown()
La salida en Markdown es limpia, legible y óptima para procesamiento por LLM. Si algo sale mal en la extracción, podés inspeccionar el archivo intermedio directamente.
La Pieza Que Lo Hace Productivo: Pydantic + Structured Outputs
Este es el insight central. Una llamada estándar de chat completion devolverá texto que parece JSON — hasta que no lo es. Los nombres de campos se desvían, los campos opcionales se omiten silenciosamente, las estructuras anidadas se aplanan inesperadamente. Ejecutar eso contra cientos de documentos significa que tu base de datos se llena lentamente de inconsistencias que son costosas de arreglar después.
OpenAI Structured Outputs cambia el contrato. En lugar de pedirle al modelo que "por favor responda en JSON", pasás un modelo Pydantic como parámetro response_format. La API garantiza que la salida conforma ese esquema — validada antes de que llegue a tu código.
from pydantic import BaseModel
from typing import List, Optional
class Experience(BaseModel):
company: str
location: Optional[str]
role: str
start_date: Optional[str]
end_date: Optional[str]
responsibilities: Optional[List[str]]
class Curriculum(BaseModel):
full_name: str
email: str
phone: Optional[str]
summary: Optional[str]
experience: List[Experience]
education: Optional[List[Education]]
skills: Optional[List[Skill]]
languages: Optional[List[Language]]
certifications: Optional[List[str]]
La llamada a la API es directa:
from openai import OpenAI
client = OpenAI()
response = client.beta.chat.completions.parse(
model="gpt-4o-mini-2024-07-18",
messages=[
{
"role": "user",
"content": f"Extract all candidate data from this CV:\n\n{markdown_text}"
}
],
temperature=0,
max_tokens=15000,
response_format=Curriculum,
)
data = response.choices[0].message.parsed
temperature=0 es deliberado — esto es extracción, no generación. La salida determinística es el objetivo. El modelo se comporta como un operador de carga de datos inteligente: lee el documento y completa los campos del esquema, nada más.
Caché: Por Qué Importa Más de Lo Que Pensarías
Un pipeline que reprocesa cada documento en cada ejecución no es un pipeline — es un script que te da miedo ejecutar dos veces. El mecanismo de caché usa hashes SHA-256 del contenido de los archivos almacenados en un archivo plano .hashes.txt.
import hashlib
def calculate_file_hash(file_path: str) -> str:
hasher = hashlib.sha256()
with open(file_path, "rb") as f:
for chunk in iter(lambda: f.read(8192), b""):
hasher.update(chunk)
return hasher.hexdigest()
def is_already_processed(file_path: str) -> bool:
file_hash = calculate_file_hash(file_path)
with open(".hashes.txt", "r") as f:
existing = f.read().splitlines()
return file_hash in existing
La lectura chunked en modo binario mantiene el uso de memoria constante sin importar el tamaño del archivo. El chequeo de hash cuesta microsegundos y ahorra una llamada a la API que cuesta dinero real. Con gpt-4o-mini, cada CV cuesta aproximadamente $0.002 — insignificante por documento, pero no si estás reprocesando 500 archivos cada mañana.
El Mismo Patrón Se Extiende a Facturas
Una de las señales más claras de que una arquitectura es sólida es cuán fácilmente acomoda un segundo caso de uso sin cambios estructurales. Después de validar el pipeline de CVs, apliqué el mismo patrón a la extracción de facturas — un tipo de documento completamente diferente con campos distintos (CUIT, CAE, líneas de ítems, desglose de impuestos).
El único cambio fue el modelo Pydantic. El pipeline — descubrimiento, hashing, conversión Docling, llamada a OpenAI, salida Excel — fue idéntico. Este es el valor de separar la definición del esquema de la lógica de extracción.
Resultados
El pipeline se ejecuta diariamente via cron. Una carpeta de CVs que antes requería una mañana dedicada de carga manual de datos ahora produce un libro Excel completamente estructurado y multi-hoja — candidatos, historial laboral, educación, habilidades, certificaciones — cada uno en su propia hoja normalizada, con una clave foránea vinculando de vuelta al registro del candidato.
El tiempo del equipo de RRHH pasó de transcripción a análisis. Ese es el resultado real que vale la pena medir.
Conclusiones Clave
La combinación de Docling, OpenAI Structured Outputs y Pydantic no es solo un stack conveniente — es una decisión de arquitectura. Cada componente tiene un rol específico:
- Docling maneja la impredecibilidad de los formatos PDF antes de que el LLM vea el documento
- Pydantic define el contrato al que tus datos deben conformarse
- Structured Outputs aplica ese contrato a nivel de API, no en post-procesamiento
- Caché SHA-256 hace que el pipeline sea seguro de ejecutar repetidamente sin desperdicio
Cualquiera de estas piezas aislada es útil. Juntas, producen algo que realmente podés correr en producción.
Explorá el Proyecto
La implementación completa — incluyendo el notebook de extracción de facturas y el código de formateo Excel — está disponible en GitHub:
github.com/Joaquin-Urruti/openai-structured-outputs
Si estás evaluando si este tipo de pipeline se ajusta a un problema de procesamiento de documentos en tu organización, estoy feliz de conversarlo. Podés contactarme via LinkedIn o agendar una llamada directamente.